The headline result: auto-generated phonetic labels are useful when human labels are scarce, but after roughly 20 to 30 hours of human annotation they can stop helping and even hurt cross-dialect robustness.
The everyday problem
A speech recognizer writes words. A phonetic transcriber tries to write sounds. That distinction matters for pronunciation learning, speech therapy, accent research, and any tool that needs to notice how a word was said rather than only guessing which word was meant.
The catch is that expert phonetic annotation is slow and expensive. A common shortcut is grapheme-to-phoneme labeling: give a model the text and ask it to predict the expected pronunciation. That creates lots of labels cheaply, but it also risks teaching the model an idealized pronunciation instead of the sound in the recording.
What we tested
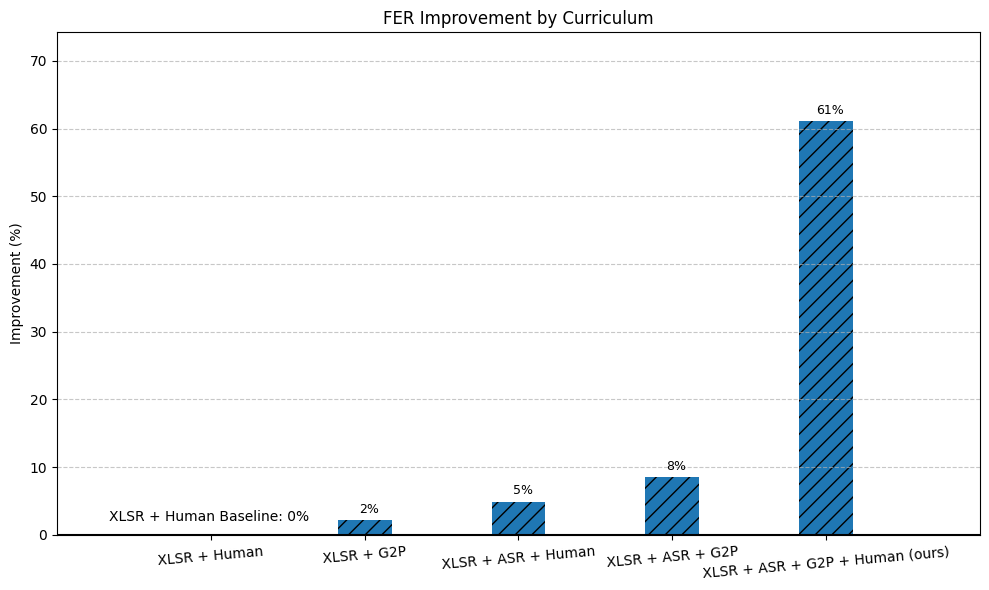
We studied English phonetic transcription across native, non-native, and post-stroke speech using a curated 80-hour benchmark. Then we asked a practical scaling question: when should a team spend its next dollar on more expert labels, and when is synthetic supervision good enough?
The surprising answer is not "more data always wins." G2P labels are helpful in the low-data regime. Once there is a meaningful amount of human annotation, the better recipe is strong ASR pretraining plus carefully curated human labels. That recipe achieved a 2.3x reduction in weighted phone feature error rate over prior systems, with gains on non-native and aphasic speech.
Why it matters
The work pushes against a tempting story in speech ML: if labels are cheap, scale them up. For inclusive speech systems, label quality and dialect coverage can matter more than raw quantity. A pronunciation tutor, clinical tool, or linguistic analysis pipeline should not become confident by averaging away the very differences it needs to hear.